WrenAI
综合介绍
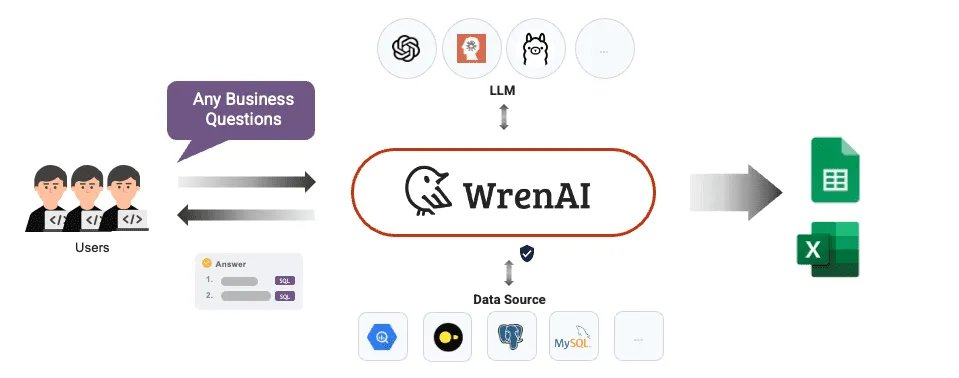
WrenAI 是一个开源的生成式商业智能(GenBI)代理,它让用户能够通过自然语言与数据库进行交互。无论用户是否具备技术背景,都可以使用日常语言提问,WrenAI 会自动将其转化为精确的SQL查询,并生成数据图表和AI分析洞察。该工具的核心在于其语义层(Semantic Layer),它通过一个建模定义语言(MDL)来预先定义业务指标和数据关系,确保大语言模型(LLM)在理解业务问题时能够准确无误,从而生成可靠的结果。WrenAI 的目标是简化数据访问的流程,让团队中的每一个人都能快速地从数据中获得见解,而无需编写复杂的SQL代码。它支持连接多种主流数据库,并可以与不同的商业或开源大语言模型集成,为企业提供了一个可定制、可嵌入的数据分析解决方案。
功能列表
- 自然语言转SQL (Text-to-SQL):用户可以使用中文或英文等自然语言进行提问,系统会自动生成精确的SQL代码并查询数据库。
- 生成式商业智能洞察 (GenBI Insights):不仅返回数据结果,还能自动生成AI撰写的业务摘要、数据图表和相关报告,为决策提供直接的上下文。
- 语义层 (Semantic Layer):通过建模定义语言(MDL)对数据库的模式、指标和表关联进行编码,这可以规范业务逻辑,确保大语言模型输出结果的准确性和一致性。
- AI驱动的电子表格:提供一个类似电子表格的交互界面,允许非技术用户导入数据后,使用自然语言指令来清洗、筛选或丰富数据集,简化了数据处理的复杂度。
- 可嵌入的API:提供API接口,开发者可以轻松地将文本查询和图表生成功能集成到自己的应用程序、SaaS产品或聊天机器人中。
- 支持多种数据源:能够连接到市面上主流的数据仓库和数据库,例如BigQuery、PostgreSQL、MySQL、Snowflake、Redshift等。
- 兼容多种大语言模型 (LLM):支持与OpenAI、Google Gemini、Anthropic、Ollama等多种模型集成,用户可以根据需求选择最适合的模型。
- 检索增强生成 (RAG) 就绪:通过其语义层,为数据库的元数据提供优化,使其更适合大语言模型进行信息检索,提高了Text-to-SQL的准确率和安全性。
使用帮助
WrenAI 提供两种主要的使用方式:本地环境部署和官方的Wren AI Cloud托管服务。对于大多数希望快速上手或进行测试的用户来说,本地部署是一个简单直接的选择,整个安装过程通常在3分钟内即可完成。
本地安装与启动(使用Docker)
在本地环境中运行WrenAI的最简便方法是使用Docker。这需要你的电脑上已经安装了Docker和Docker Compose。
第一步:下载配置文件
首先,从WrenAI的GitHub仓库下载docker-compose.yml文件。你可以使用curl命令来完成:
curl -o docker-compose.yml https://raw.githubusercontent.com/Canner/WrenAI/main/docker/docker-compose.yml
第二步:配置大语言模型(LLM)
WrenAI需要连接一个大语言模型来理解自然语言并生成SQL。你需要编辑刚刚下载的docker-compose.yml文件,填入你选择使用的大模型的API密钥。
打开docker-compose.yml文件,找到wren-ai-service部分下的environment配置。下面以配置OpenAI的GPT模型为例:
services:
wren-ai-service:
# ... 其他配置 ...
environment:
# - WREN_AI_API_KEY= # 如果需要,可以在这里设置Wren AI的API密钥
- LLM_API_KEY=sk-xxxxxx # 将 sk-xxxxxx 替换成你的OpenAI API密钥
- LLM_PROVIDER=openai # 指定LLM提供商为openai
# - LLM_MODEL=gpt-4-turbo # 你可以选择指定一个模型,默认是gpt-3.5-turbo
# ... 其他配置 ...
你需要将LLM_API_KEY的值替换成你自己的密钥。WrenAI支持多种模型,如需使用Google Gemini、Anthropic Claude或通过Ollama运行的本地模型,可以参考官方文档中的配置示例进行修改。
第三步:启动WrenAI
保存配置文件后,在终端中运行以下命令来启动WrenAI服务:
docker-compose up
当你在终端看到启动完成的日志后,WrenAI就已经在你的本地成功运行了。
第四步:访问WrenAI界面
打开你的网络浏览器,访问 http://localhost:3000。你将看到WrenAI的用户界面,可以开始连接数据源并进行查询。
核心功能操作流程
成功部署并进入WrenAI界面后,主要的操作流程分为三步:连接数据源、定义语义模型、进行自然语言查询。
1. 连接你的数据源
- 在WrenAI界面的引导下,选择“添加数据源”。
- 从列表中选择你要连接的数据库类型,例如PostgreSQL、BigQuery或Snowflake等。
- 填入数据库的连接信息,包括主机地址、端口、用户名、密码和数据库名称。
- 点击“连接”并进行测试,确保WrenAI可以成功访问你的数据库。
2. 定义语义模型 (MDL)
这是WrenAI区别于其他Text-to-SQL工具的关键步骤。通过定义语义模型,你可以告诉AI你的业务逻辑,从而极大提升查询的准确率。
- 创建模型:在数据源连接成功后,你可以为数据库中的表创建对应的“模型”。每个模型代表一个业务概念,例如“用户”或“订单”。
- 定义指标 (Metric):在模型中,你可以创建“指标”。指标是业务分析中常用的计算值,例如“总销售额”、“日活跃用户数”或“平均客单价”。
- 例如,你可以创建一个名为
total_revenue的指标,其计算方式定义为SUM(price)。
- 例如,你可以创建一个名为
- 定义关系 (Relation):如果你的查询需要跨越多个表,你需要定义它们之间的“关系”。例如,你可以定义
orders表通过user_id字段与users表相关联。 - 通过这种方式,当你用自然语言提问“过去一个月每个用户的总销售额是多少?”时,WrenAI能够理解“总销售额”就是你定义的
total_revenue指标,并且知道如何将orders表和users表关联起来,最终生成一个准确的SQL查询。
3. 进行自然语言查询和分析
完成语义层定义后,你就可以开始用最自然的方式与数据对话了。
- 提问:在查询界面,直接在输入框中用中文或英文输入你的问题,例如:“显示上周新增的用户数量”或“哪些产品的库存低于100?”。
- 查看结果:WrenAI会实时将你的问题转化为SQL代码(你可以查看并验证生成的SQL),然后执行查询,并将结果以表格形式展示出来。
- 图表生成:除了表格数据,WrenAI通常会自动推荐合适的图表类型(如折线图、柱状图)来对结果进行可视化。你也可以手动选择图表类型。
- AI洞察:在数据和图表的旁边,WrenAI的GenBI功能会提供一段由AI生成的文字摘要,解读数据结果并指出其中可能存在的业务洞察。
通过以上步骤,即便是没有SQL基础的团队成员,也能独立完成从数据连接、业务建模到最终的数据查询与分析的全过程,极大地提升了数据驱动决策的效率。
应用场景
- 为非技术团队赋能对于市场营销、销售、运营或产品团队的成员来说,他们经常需要数据来支持决策,但又不懂如何编写SQL。WrenAI可以让他们直接用自然语言提问,如“上个季度哪个营销渠道带来的新用户最多?”或“用户留存率最高的三个产品功能是什么?”,从而独立地完成数据探索,无需再排队等待数据工程师的帮助。
- 加速数据分析师的工作流程对于数据分析师而言,许多日常的数据提取请求是重复且基础的。WrenAI可以作为一个高效的助手,快速生成基础查询的SQL代码和图表。分析师可以将更多精力投入到更深层次的复杂分析和建模工作中,而不是消耗在临时的数据拉取请求上。
- 嵌入现有应用中提供AI分析能力软件开发者可以将WrenAI通过API集成到自己的SaaS产品或内部工具中。例如,一个CRM系统可以集成WrenAI,让销售人员能够用自然语言查询客户数据;一个项目管理工具可以集成它,让项目经理能够快速生成关于项目进度的报表。
- 统一全公司的业务指标由于WrenAI依赖于一个集中的语义层来定义业务指标(例如“活跃用户”、“利润率”),它可以确保整个公司在讨论和分析数据时,使用的是同一个标准和口径。这避免了因指标定义不一致而导致的数据混乱和决策失误。
QA
- 问题:WrenAI支持哪些类型的数据库?答案:WrenAI 支持多种主流的关系型数据库和数据仓库,包括PostgreSQL、MySQL、Microsoft SQL Server、BigQuery、Snowflake、Redshift、ClickHouse、DuckDB、Athena和Oracle等。
- 问题:使用WrenAI是否安全?我的数据会发送给大语言模型吗?答案:WrenAI 在设计上注重安全性。它仅会将数据库的元数据(即表结构、列名、数据类型等)和你在语义层中定义的模型信息发送给大语言模型用于生成SQL,而不会发送数据库中的实际业务数据。这确保了你的敏感数据保留在本地,不会被泄露。
- 问题:如果WrenAI生成的SQL不准确怎么办?答案:WrenAI的准确性高度依赖于其语义层的定义。如果生成的SQL不准确,通常可以通过优化语义模型来解决,例如更清晰地定义指标、添加表之间的关系或为字段提供更详细的描述。此外,系统也包含一个反馈循环机制,允许用户修正查询,帮助模型不断学习和改进。
- 问题:我可以使用自己本地部署的开源大语言模型吗?答案:可以。WrenAI 支持通过Ollama连接本地运行的开源大语言模型(如Llama、Mistral等)。你只需在配置文件中将LLM提供商设置为
ollama并指定相应的模型名称即可。 - 问题:WrenAI是完全免费的吗?答案:WrenAI本身是一个开源项目,采用AGPL-3.0许可证,你可以免费下载、部署和使用。同时,其背后的公司Canner也提供了名为Wren AI Cloud的商业托管服务,为企业提供免部署、有技术支持的解决方案。